18 Bloqueabilidad del compilador de algoritmos numéricos

Actualmente estamos viviendo la época tecnología, donde los microprocesadores, aumentando el poder de computo exponencialmente, mientras los diseños de memoria no han podido seguir el ritmo de estos avances, lo cual provoca un desface entre la velocidad de memoria y computo ha provocado el diseño especifico de arquitecturas demasiado complicadas para la memoria, donde los programadores se han visto sometidos al desarrollo de código especifico para ciertos tipos de estructura de memoria para la máquina, Dicho artículo describe la tecnologías de compiladores para omitir el diseño especifico para cada maquina y sistemas de arquitecturas, donde se revela en dicha investigación que mediante el uso de optimizaciones del compilador muchos algoritmos numéricos se producen de manera natural manteniendo un buen uso de la memorias.
18.1 Introducción
La tendencia de ahora es conseguir el mayor poder de computo posible, teniendo muchos más núcleos y ciclos por segundo en cada procesador nuevo de salida, donde dicho poder de computo no le favorece a la memoria, ya que la misma no puede manejar la velocidad que el procesador le envía instrucciones específicas, obstruyendo los canales de información, concluyendo en un fatal rendimiento en diferentes estructuras del computador.
Llevando así a los programadores a crear código específico para conjuntos específicos de hardware de un computador o haciéndolo de forma global donde el poder de computo es desaprovechado por dichos problemas de velocidades y saturación.
Existe una gran historia sobre la optimización de los compiladores y la independencia de dichos sistemas mencionados para obviar el desface y ser compatible de para todo computador, lo cual nos lleva la tecnología de vectorización que hace posible escribir softwares vectoriales independientes del computador en un sub-lenguaje Fortran 77 donde se sostiene que esta permitirá se posible lograr el mismo éxito para la gestión de la memoria en procesadores escalares. Siendo precisos la tecnología de compilación mejorada permitirá las aperturas de múltiples puertas para el desarrollo de software en un algoritmo más natural.
18.2 Artículo
Material y Recursos
Uno de los mayores experimentos que se pueden aplicar para la viabilidad de este enfoque es la generación automática los algoritmos de bloque en LAPACK a partir de algoritmos correspondientes expresados en Fortran 77.
Fortran
Fortran fue uno de los primeros lenguajes de programación de alto nivel. Una de las características más destacadas de las aplicaciones Fortran es que son portátiles entre plataformas de máquinas. Los programas Fortran pueden ejecutarse en cualquier máquina que tenga un compilador Fortran. A diferencia de otros lenguajes de programación, Fortran tiene un conjunto estricto de reglas con respecto al formato del código fuente.
Fortran 77es uno de los lenguajes de programación más simples y es muy fácil de aprender. Es uno de los mejores lenguajes de programación para operaciones o computación matemática con alta disponibilidad en bibliotecas Fortran 77 eficientes. De hecho, Fortran 77 se considera una de las mejores opciones para bucles o matrices de tiempo crítico.
LAPACK
LAPACK (Paquete de álgebra lineal) es una biblioteca FORTRAN 77 con licencia BSD que proporciona rutinas para resolver los problemas más comunes en álgebra lineal numérica, como: - Ecuaciones lineales. - Soluciones de mínimos cuadrados de sistemas de ecuaciones lineales. - Problemas de valores propios. - problemas de valores singulares.
LAPACK actualmente en desarrollo tiene como objetivo proporcionar una biblioteca portátil de álgebra lineal para computadoras de alto rendimiento. LAPACK hará uso de los BLAS Nivel 1, 2 y 3 para realizar operaciones básicas. Un enfoque principal de este proyecto es implementar versiones bloqueadas de una serie de algoritmos para aprovechar el mayor paralelismo y la localidad de datos mejorada del Nivel 3 BLAS.
Transfondo
La herramienta fundamental disponible para el compilador es la misma herramienta utilizada en la vectorización y la paralelización, es decir, la dependencia. Existe una dependencia entre dos sentencias si existe un camino de remolque de control desde la primera sentencia hasta la segunda, y ambas sentencias hacen referencia a la misma ubicación de memoria, esto para dar inicio al experimento que se realizó en la investigación de Steve C. Ken K. (1992). Compiler of Numerical Algorithms (1.a ed., Vol. 1). CRPC-TR92208-S.
Reutilizando Cache
Cuando se aplica a la gestión de la jerarquía de memoria, una dependencia puede considerarse como una oportunidad de reutilización. Hay dos tipos de reutilización: temporal y espacial. La reutilización temporal se produce cuando una referencia en un bucle accede a datos a los que se ha accedido previamente en la iteración actual o anterior de un bucle. La reutilización espacial ocurre cuando una referencia accede a datos que están en la misma línea de caché que algún acceso anterior, como se presenta en el siguiente ciclo.
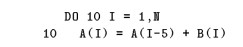
Figura 18.1: Linear Algebra pacKage. (1900). netlib. Recuperado 2 de mayo de 2022
Bloqueo del espacio de iteración
Para mejorar el comportamiento de la memoria de los bucles que acceden a más datos en la caché, el espacio de iteración de un bucle se puede agrupar en bloques cuyos conjuntos de trabajo son lo suficientemente pequeños para que la caché capture la información y usando reutilización temporal disponible.
División de conjutos de índices
El bloqueo del espacio de iteración no siempre se puede aplicar directamente como se muestra en la sección anterior. A veces, las restricciones de seguridad solo permiten una aplicación parcial del bloqueo. En estos casos, se puede aplicar una transformación llamada división de conjuntos de índices. La división de conjuntos de índices crea varios bucles a partir de un bucle original y cada nuevo bucle itera sobre porciones que no se cruzan del espacio de iteración original. El orden de ejecución no cambia y el espacio de iteración original aún se ejecuta por completo.
Bloqueo del espacio de iteración
Para mejorar el comportamiento de la memoria de los bucles que acceden a más datos en la caché, el espacio de iteración de un bucle se puede agrupar en bloques cuyos conjuntos de trabajo son lo suficientemente pequeños para que la caché capture la información y usando reutilización temporal disponible.
Espacios de iteración triangulares
Si el espacio de iteración de un ciclo no es rectangular, el bloqueo del espacio de iteración no se puede aplicar directamente. El intercambio de bucles que iteran sobre regiones triangulares requiere la modificación de los límites del bucle para preservar la semántica del bucle. Por lo tanto, el bloqueo de regiones triangulares también requiere una modificación del límite del bucle.
Espacios de iteración trapezoidal
Si bien el método anterior se aplica a muchos de los espacios de iteración comunes de forma no rectangular, todavía hay algunos bucles importantes que no manejará. En álgebra lineal, sísmica y códigos de ecuaciones diferenciales parciales, se producen bucles con espacios de iteración de forma trapezoidal.
Patrón de dependencia complejo
En algunos casos, no es solo la forma del espacio de iteración lo que presenta dificultades para el compilador, sino también los patrones de dependencia dentro del ciclo.
Inspección IF
Además de las formas del espacio de iteración y los patrones de dependencia, también se deben considerar los efectos del flujo de control sobre el bloqueo. Puede darse el caso de que un bucle interno esté protegido por una declaración IF para evitar cálculos innecesarios. Considere el siguiente código de multiplicación de matrices que se toma de la rutina SGEMM de BLAS.
Sistemas de ecuaciones lineales
El objetivo de LAPACK es reemplazar los algoritmos en LINPACK y EISPACK con algoritmos de bloque que tienen un mejor rendimiento de caché. Desafortunadamente, los diseñadores de LAPACK han logrado un rendimiento adicional a expensas de la independencia de la máquina.
Para adaptar sus núcleos de una máquina a otra, un programador debe realizar una optimización manual específica de la máquina en cada subrutina LAPACK para obtener un alto rendimiento. Por el contrario, creemos que los programadores deberían expresar cada kernel en una forma independiente de la máquina, con el compilador manejando los detalles de optimización específicos de la máquina.
Descomposición LU sin pivotar
La eliminación gaussiana es una forma de descomposición LU donde la matriz A se descompone en dos matrices L y U, tales que:
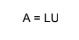
Figura 18.2: Ecuación
La eliminación gaussiana es una forma de descomposición LU donde la matriz A se descompone en dos matrices L y U, tales que:
Usando esta ecuación, se deriva un algoritmo para la descomposición LU sin pivotar usando la eliminación gaussiana
Descomposición LU con pivote parcial
Descomposición con pivote parcial, Aunque el compilador puede descubrir el potencial de bloqueo en la descomposición de LU sin pivotar utilizando el algoritmo Index SetSplit, no se puede decir lo mismo cuando se agrega el pivote parcial (consulte la Figura 7 para la descomposición de LU con pivote parcial). En el algoritmo de pivoteo parcial existe una nueva recurrencia.
Householder QR
La clave de la eliminación gaussiana es la multiplicación de la matriz A por una serie de matrices triangulares inferiores elementales que introducen ceros debajo de cada elemento diagonal. Cualquier clase de matriz que tenga esta propiedad puede usarse para resolver un sistema de ecuaciones lineales.
Given QR
Otra forma de matriz ortogonal que se puede utilizar en la descomposición QR es la matriz de rotación de Givens. Actualmente no conocemos el mejor algoritmo de bloques para derivar del algoritmo de puntos, por lo que mostramos que IndexSetSplit y IF- inspection tienen una aplicación más amplia.
Extensión de idioma
El examen de la descomposición QR con transformaciones de Householder muestra que un compilador no puede derivar algunos algoritmos de bloque a partir de sus algoritmos de punto correspondientes. Para mantener el objetivo de estilos de codificación independientes de la máquina, se debe hacer posible la expresión de estos tipos de algoritmos de bloque en una forma independiente de la máquina. Específicamente, se debe indicar al compilador que seleccione el factor de bloqueo dependiente de la máquina para un algoritmo automático.
18.3 Conclusión
Los resultados de este estudio son alentadores: podemos bloquear bucles triangulares y trapezoidales y hemos encontrado que muchos de los problemas introducidos por patrones de dependencia complejos pueden superarse mediante el uso de la transformación conocida como “index-set splitting”. En muchos casos, la división de conjuntos de índices produce códigos que exhiben un rendimiento al menos tan bueno como los mejores algoritmos de bloque producidos por los desarrolladores de LAPACK. Además, hemos demostrado que el conocimiento sobre qué operaciones conmutan puede permitir que un compilador tenga éxito en el bloqueo de códigos que no pudieron por cualquier compilador basado estrictamente en el análisis de dependencia. Desafortunadamente, nuestro éxito no ha sido universal. Para métodos como la descomposición QR, el algoritmo de bloque no tiene un algoritmo de punto correspondiente porque los tamaños de bloque mayores que uno requieren un cálculo adicional para compensar el bloqueo.
18.4 Referencias
-
[1] [Andrew W. Appel, “Modern Compiler Implementation,Aut.Control. Vol. 1. No 1. May 1947.”]
-
[2] [Anthony J. Dos Reis , “Writing Interpreters and Compilers for the Raspberry”, Aut. Control. Vol. 1. No 2. May 1902.]
-
[3] [Ken Kennedy , “Optimizing Compilers for Modern Architectures”, Aut. Control. Vol. 6. No 1. Aug 1943.]
-
[4] [Priti Shankar, “The Compiler Design Handbook: Optimizations and Machine Code Generation”, Aut. Control. Vol. 2. No 1. Sep 1912.]
-
[5] [Rafal Swidzinski, “Discover a better approach to building, testing, and packaging your software”, Aut. Control. Vol. 4. No 1. Feb 1922.]