Recorriendo la última milla: implementación de software en múltiples clientes

José Augusto Alvarez Morán
Estudiante de Ingeniería en Ciencias y Sistemas - USAC
Palabras Clave:
Git, DevOps, patrón observador, patrón mediador.
Necesidad de personalización del software
Cuando se concibe un producto comercial de software, el equipo de diseño y producción del mismo intenta pensar de una forma lo más genérica posible respecto al diseño e implementación de este, de tal forma que pueda ser implementado casi tal y como está en la mayoría de clientes posibles.
En el caso en particular de este artículo, cuando hablamos de este producto comercial, se asume un software que permite adaptarse con fuertes modificaciones al cliente, en oposición a un software “as is” en donde el negocio y sus procesos deben adaptarse al software.
En este caso, estas implementaciones “as is” tienden a ser una utopía, ya que las empresas tienen modelos muy diversos de funcionamiento incluso respecto a las mismas necesidades, o sencillamente tienen necesidades distintas.
Esta realidad hace que un producto de software deba recibir una serie de adaptaciones y personalizaciones para su implementación final, las cuales se procura sean lo más en línea posible con el modelo original del producto que fue concebido como genérico.
Patrones de software, DevOps y metodologías ágiles como herramientas básicas
Este artículo asume tres elementos importantes que guiarán el resto del mismo, para poder ir haciendo propuestas concretas en las distintas etapas del desarrollo e implementación:
- El uso de los distintos patrones de software según fueron concebidos por el gang-of-four. [1]
Utilización de un ciclo DevOps según la definición e implementación de Verona: desarrollo, sistema de revisión y calidad, pruebas de calidad (QA), liberación y operaciones. [2]
El uso de metodologías ágiles para desarrollo.
Seleccionando los patrones de software para las personalizaciones de cada cliente
Al tener el enfoque en un producto de software genérico, el desarrollo de personalizaciones exitosas de un cliente final, puede ir guiada por los patrones observador (observer pattern) y mediador (mediator pattern) según lo propone Mustafic [3], los cuales permitirán el desarrollo de dichas personalizaciones en formato de complementos (plugins), o incluso el desarrollo completo de una personalización como un software, que se comunicará con el producto por medio de dichos patrones.
El patrón observador, establece una forma muy útil que no se limita en la interacción entre dos entidades, sino de cómo desarrollar entidades más genéricas (productos) y luego relacionarlas con las personalizaciones, dicha personalización conoce y utiliza al 100% el producto, a pesar de que el producto solo se comunica con la personalización mediante suscripciones a eventos específicos (observadores).
El patrón mediador, refuerza además este desarrollo mediante la encapsulación de objetos y la comunicación indirecta del producto y la personalización del mismo.
Manejo del repositorio Git enfocado al ciclo DevOps del producto
Es vital que, para el uso del repositorio del software a implementarse, no solo se utilice Git, sino que se use de forma tal en que permita hacer integración y entrega continua (CI / CD) desde la forma en que se utiliza el mismo, para lo cual se recomienda el uso según Driessen [4]:
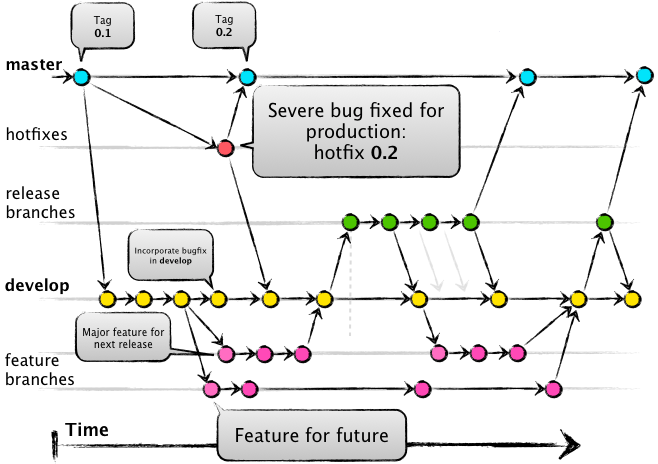
Author: Vincent Driessen (Traducida) Fuente: nvie.com
El uso de una rama master solamente para las liberaciones principales del producto.
Manejar las etiquetas (tags) de versiones sobre las liberaciones de la rama master.
El uso de una rama develop para liberaciones parciales de desarrollo (las cuales pueden considerarse alpha o beta según la etapa del software).
El uso de ramas feature para nuevas funcionalidades y ramas hotfix para correcciones de errores.
Creación de pull/merge requests desde las ramas feature y hotfix hacia la rama develop.
De esta forma, cada uno de los pull/merge requests que se proponen sobre la rama develop provocan una ejecución de elementos del ciclo DevOps, consistentes en:
La revisión automatizada y manual de calidad y estándares del software.
Ejecución de pruebas unitarias.
Ejecución de pruebas automatizadas de sistema.
Ejecución de pruebas manuales de las nuevas funcionalidades y/o correcciones.
Utilización de repositorios de implementación de clientes
Considerado que se ha manejado tanto el producto como las personalizaciones, según se ha descrito hasta ahora (cada uno en un repositorio Git e integrados por los patrones descritos), la última milla consiste justamente en llevar el software a su implementación final, considerando las personalizaciones desarrolladas.
Para esto vamos a utilizar algo que llamaremos el repositorio de implementación. Este repositorio de implementación, debe contener todas las partes necesarias para que un cliente pueda utilizar el software completo, y estructuradas de tal forma que haga sentido.
Para esto utilizaremos la versatilidad que nos dan hoy día los diferentes administradores de paquetes y auto-carga (autoload) tales como NPM en el caso de Javascript o Composer para PHP.
Asumamos, por ejemplo, el uso de PHP y Composer, considerando que PHP haya sido la solución utilizada para el desarrollo tanto del software principal (producto) como para las personalizaciones.
De esta forma, cada una de estas partes puede ser gestionada por medio de Composer, de tal forma que cada una de las mismas pueda ser incluida en un archivo composer.json que hará la inclusión de cada una de las partes y un software de implementación, en un repositorio Git de implementación de cliente, por ejemplo:
{
"name": "cliente-n",
"require": {
"software/principal": "^1.0",
"clientex/personalización-1": "^1.0",
"clientex/personalización-1": "^1.0",
"software/implementacion": "^1.0"}
}De esta forma, este repositorio es capaz no solo de incluir cada una de las partes (correctamente relacionadas entre sí), sino que además es capaz de bloquear las versiones probadas y autorizadas a ser desplegadas en el cliente específico, las cuales pueden variar o quedar atrás por múltiples razones incluyendo lógica de negocio y/o manejo de pagos de suscripción o actualización.
El software de implementación, es por tanto el que está encargado de ejecutar la integración final y las distintas etapas DevOps correspondientes a este software de implementación, a pesar de que el mismo no tiene código como tal, sino que es solo una integración de componentes. El modelo propuesto nos permite, por lo tanto:
Ejecutar pruebas automatizadas de sistema del software principal con sus personalizaciones.
Realizar una prueba completa en un ambiente staging.
Realizar una liberación final master (del repositorio de implementación) para que el cliente sea trasladado a una versión estable.
Automatizar la implementación al ambiente productivo del cliente.
Conclusiones
Cuando hay que tratar con múltiples implementaciones y elementos operativos, la simplificación en torno a la automatización de cada implementaciones es clave.
Las herramientas y metodologías modernas de desarrollo traen implícita la clave de cómo poder simplificar y poder entregar software de alta calidad, con un correcto versionamiento y suficientes personalizaciones en tiempos predecibles y lo menos propensos posibles de errores humanos.
Referencias
[1] Erich Gamma; Richard Helm; Ralph Johnson; & Jonh Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Boston, Estados Unidos: Addison-Wesley, 2009, ©1995.
[2] Joakim Verona, Practical DevOps. Birmingham, Reino Unido: Packt Publishing (16 de febrero de 2016).
[3] Asmir Mustafic, «Codementor», Modular Application Architecture - Considerations on Design Patterns, 09 enero 2018. [En línea]. Disponible en: http://bit.ly/32491x3. [Último acceso: 07 octubre 2019].
[4] Vincent Driessen, «nvie.com», A successful Git branching model, 05 enero 2010. [En línea]. Disponible en: http://bit.ly/2Or2jgw. [Último acceso: 07 octubre 2019].

