Computación paralela a través de CUDA

Erick Roberto Tejaxún Xicón
erickteja@gmail.com
Estudiante de Ingeniería en Ciencias y Sistemas - USAC
Computación paralela
La computación paralela hace referencia a la capacidad de poder realizar varias tareas al mismo tiempo. Esto aplicado a las ciencias de la computación se ha estado trabajando desde hace muchos años, casi al mismo tiempo que el inicio de la computación moderna.
Pero, ¿para qué aplicar computación paralela? La computación paralela tiene como objetivo acelerar una aplicación, es decir, reducir el tiempo de procesamiento. Por lo cual el motivo que ha traído consigo la búsqueda de un estándar para el uso de computación paralela ha sido ese, de tener problemas que requieren gran cantidad de capacidad y tiempo de cómputo. Por ejemplo, un problema de simulación de colisiones de partículas, utilizando un algoritmo secuencial y usando un solo procesador podría llevar años en su finalización.
En un principio, cuando se contaba con una computadora con un único procesador, el paralelismo se aplicó creando una red de computadoras dentro de las cuales se pudiera trabajar en un mismo problema. Es decir, cada computadora conectada a esta red, tendría la tarea de trabajar sobre una porción del problema. Minimizando así el tiempo de computación para la solución del problema. Esto se sigue aplicando hoy en día y podemos encontrar sitios especializados en este tema, que llevan el recuento y el listado de las supercomputadoras más potentes del mundo como top500.org.
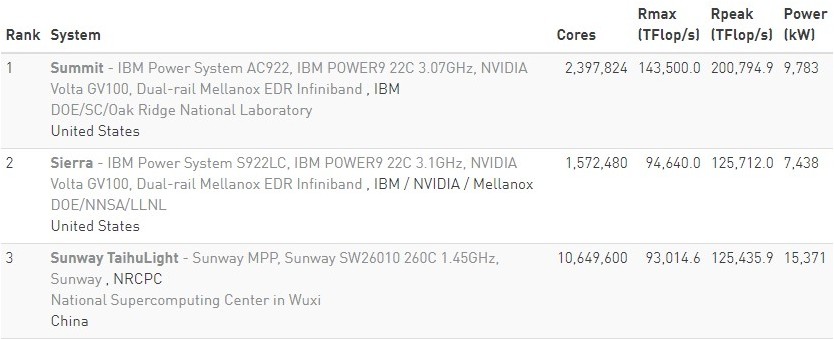
Imagen 1 - Fuente: Top500.org
Como vemos en la ilustración anterior tomada de la página Top500.org, las supercomputadoras en la actualidad cuentan con millones de núcleos que pueden trabajar en conjunto y generar un throughput en el orden de miles de Teraflops por segundo. Cabe mencionar que estas supercomputadoras están en centros de investigación en países del primer mundo.
A través del tiempo, la computación paralela ha sido un tema estudiado de sobremanera ya que tiene muchas aplicaciones en cualquier ámbito. Quizá en algún futuro se pueda contar en nuestra escuela con un curso sobre el tema como el que se cuenta ya en la Escuela de Ciencias Físicas y Matemáticas el cual tiene un enfoque científico donde se tratan de resolver problemas de sistemas dinámicos, corridas de método Montecarlo entre otros.
Se han diseñado diferentes arquitecturas de memoria para la computación paralela. Esto debido a que el principio de esta es que se debe de trabajar sobre un mismo conjunto de datos que conforman todo el problema en sí. Entre estas arquitecturas tenemos la arquitectura de acceso uniforme a memoria (UMA por sus siglas en inglés), arquitectura de acceso no uniforme a memoria (NUMA por sus siglas en inglés).
Dentro del paralelismo a nivel de datos existen cuatro técnicas básicas las cuales son: única instrucción, múltiple datos (SIMD siglas en inglés). Múltiple instrucciones, múltiple datos (MIMD), única instrucción, un dato (SISD) y múltiple instrucción, un dato (MISD). La más utilizada es la de única instrucción, múltiples datos.
¿Qué es CUDA?
CUDA (Arquitectura unificada de dispositivos de cómputo) es una arquitectura de procesamiento en paralelo creada por la empresa especializada en tarjetas gráficas Nvidia, en la que se trata de aprovechar la capacidad y potencia de sus GPU (Unidad de procesamiento gráfico) como una alternativa al procesamiento en CPU’s tradicionales.
CUDA es una tecnología basada tanto en hardware como en software. En hardware al hacer que la arquitectura de sus tarjetas gráficas estén preparadas para poder explotar el paralelismo al contar con varios conjuntos de procesadores que reciben una misma instrucción para un vasto conjunto de datos. Entre ellas encontramos las arquitecturas Maxwell, Pascal entre otras.
En cuanto a software, CUDA provee una plataforma en forma de librerías y compiladores para que se puedan escribir programas que aprovechen el hardware de las GPUs dándole total control al desarrollador.
¿Por qué CUDA?
Existen diferentes arquitecturas de computación paralela. Estás tienen su máximos exponentes en especificaciones y estándares tan potentes y utilizados como OpenMP2 o bien MPI los cuales en la actualidad son los que suelen ser utilizados en la mayoría de centros de investigación.
Lo que trata de hacer CUDA es desviarse de lo que buscan los procesadores tradicionales como los de la serie Xenon de Intel, en donde sus núcleos son muchísimo más rápidos que un núcleo de una GPU estándar (hasta 4.5 Ghz vs 1096 – 1020 Mhz) en vez de enfocarse en la rapidez de los núcleos, se enfoca en la cantidad de estos núcleos. Así, en vez de tener 24 o 36 núcleos a una velocidad de 4.5Ghz, una GPU cuenta con 640, 1020 y hasta 1280 núcleo (en las tarjetas de video serie titán) con una frecuencia de reloj de 1078Mhz.
Esto permite aprovechar la técnica SIMD de simple instrucción para múltiple data. Por esa razón, CUDA se acopla demasiado bien para aplicar computación paralela y así maximizar el rendimiento de las aplicaciones.
Cabe mencionar que CUDA es transparente al sistema operativo, es decir que CUDA ofrece soporte para sistemas operativos Windows, GNU/Linux y para sistemas operativos MacOs. Su rendimiento no depende del sistema operativo en sí, si no en las condiciones de trabajo que se encuentre la máquina o clúster sobre el cual se hará funcionar la aplicación.
Paralelizar una aplicación a través de CUDA
Para comprobar, analizar y determinar el mejoramiento real de usar computación paralela en un problema real (hay que tener en cuenta que no todos los problemas se pueden paralelizar ya que por lo general son inherentemente secuenciales) se utilizarán una aplicación llamada ScanSky, desarrollada y escrita por la Dra. Ana Moretón Fernández, el Dr. Javier Fresno y el Dr. Arturo González-Escribano del grupo de investigación Trasgo3, de la escuela superior de ingeniería informática de la Universidad de Valladolid, España, como parte de la práctica número tres del curso de computación paralela.
Esta aplicación recibe como entrada un archivo que consiste en números separados por un salto de línea tal y como se muestra en la siguiente imagen. Estos números representan el color de cada uno de los píxeles de una imagen. El objetivo de esta aplicación es determinar con precisión el número de cuerpos celestes presentes en dicha imagen.
Imagen 2 - Fuente: Elaboración propia.

Imagen 3 - Fuente: Nasa
Imagen 4 - Fuente: Elaboración propia.
El programa determina el número de cuerpos celestes compara un pixel con los pixeles de sus alrededores para determinar si se trata o no del mismo cuerpo celeste, comenzando de izquierda a derecha y de arriba hacia abajo, es decir empezando con la coordenada (0,0) hasta llegar a la coordenada (n,n) .
El código del programa secuencial, escrito en lenguaje de programación C, se puede encontrar en github 3, subido con los permisos pertinentes de los autores. Y este cuenta con el programa secuencial que cuenta los planetas en el archivo de entrada, apoyado con unas librerías desarrolladas por el mismo grupo de investigación que permite obtener el tiempo exacto de ejecución y otra librería que permite conectarse hacia el sistema Tablón 5 que permitía correr el sistema dentro del clúster de la escuela superior de ingeniería informática.
Para esta prueba, vamos a comparar los tiempos de ejecución en diferentes condiciones obedeciendo las siguientes especificaciones:

Imagen 5 - Fuente: Especificaciones corrida secuencial de ScanSky - Elaboración propia.

Imagen 6 - Fuente: Especificaciones corrida paralela de ScanSky a través de CUDA - Elaboración propia.

Imagen 7 - Fuente: Especificaciones corrida paralela ScanSky a través de CUDA. Sistema Tablón, UVa - Elaboración propia.
Para estas corridas de prueba se utilizaron 3 tipos de cargas de datos como se indica a continuación:

Imagen 8 - Fuente: Set de datos para pruebas con el programa ScanSky - Elaboración propia.
Resultados

Imagen 9 - Fuente: Elaboración propia.

Imagen 10 - Fuente: Elaboración propia.

Imagen 11 - Fuente: Elaboración propia.
Como podemos observar en la gráfica anterior, las tres configuraciones tienen una forma similar, pero con una pendiente mucho más pequeña en el caso de la configuración número 3. Y vemos que utilizando la GPU de la computadora de la configuración número 1, obtenemos un resultado que minimiza sobre 3 veces el tiempo utilizado en la aplicación en forma secuencial. Obviamente el código en paralelo utilizando CUDA es mejorable, pero en principio vemos como la computación paralela puede ayudarnos a reducir el tiempo de procesamiento en set de datos pequeños, pero cuando se utilicen set de datos muchos mayores, la diferencia será demasiado grande.
Conclusiones
La computación paralela es un tema muy importante en el área de las ciencias de computación y además en muchas industrias como la de la medicina, ingeniería, química, física, aviación, videojuegos entre muchas otras.
Vemos como en un programa no tan complejo, la programación paralela nos ha ayudado a realizar una aceleración de hasta tres veces menor con un set de datos mediano, pero con set de datos mayores, la aceleración será mucho mayor a comparación de su versión secuencial.
Es necesario que como escuela de ciencias y sistemas estemos anuentes a estas tendencias tecnológicas que no son recientes pero que tienen mucho auge y demanda en muchas industrias y que podría ser otra ventana de salida para los futuros egresados de nuestra escuela de ciencias y sistemas.
Referencias bibliográficas:
Programa del curso de física computacional, ECFM, USAC. Disponible en (1)
Especificación para computación paralela por medio de paso de mensajes (API). OpenMP (2))
Grupo de investigación, Trasgo. Universidad de Valladolid, España. (3)
Programa ScanSky paralelo y su conversión a su equivalente en versión paralela a través de CUDA. (4)
WOMPAT 2001, International Worskshop on OpenMP Aplication, “OpenMp Shared Memory Parallel Programing”, Purdue University, School of Electrical and Computer Engineering.
Nvidia, Cuda Toolkit documentation. En línea Consultado el 01/04/2019.
Michael Skuhersky, MIT. “Introduction to parallel computing”,En línea consultado el 03/04/2019.
